The information in this topic assumes that you are using a performance optimization methodology and have analyzed the application type you are optimizing.
After profiling your application to determine where best to spend your time, attempt to discover what optimizations and what limitations have been imposed by the compiler. Use the compiler reports to determine what to try next.
Depending on what you discover from the reports you may be able to help the compiler through options, pragmas, and slight code modifications to take advantage of key architectural features to achieve the best performance.
The compiler reports can describe what actions have been taken and what actions cannot be taken based on the assumptions made by the compiler. Experimenting with options and pragmas allows you to use an understanding of the assumptions and suggest a new optimization strategy or technique.
Helping the Compiler
You can help the compiler in some important ways:
-
Read the appropriate reports to gain an understanding of what the compiler is doing for you and the assumptions the compiler has made with respect to your code.
-
Use specific options, intrinsics, libraries, and pragmas to get the best performance from your application.
For example, if your code is attempting to constantly compute square roots of single precision values, you can gain performance by using the appropriate intrinsic for single precision data type; for example, sqrtf() instead of sqrt() in C.
See Applying Optimization Strategies for other suggestions.
Memory Aliasing For IA-64 Architectures
Memory aliasing is the single largest issue affecting the optimizations in the Intel® compiler for IA-64 architecture based systems. Memory aliasing is writing to a given memory location with more than one pointer. The compiler is cautious to not optimize too aggressively in these cases; if the compiler optimizes too aggressively, unpredictable behavior can result (for example, incorrect results, abnormal termination, etc.).
Since the compiler usually optimizes on a module-by-module, function-by-function basis, the compiler does not have an overall perspective with respect to variable use for global variables or variables that are passed into a function; therefore, the compiler usually assumes that any pointers passed into a function are likely to be aliased. The compiler makes this assumption even for pointers you know are not aliased. This behavior means that perfectly safe loops do not get pipelined or vectorized, and performance suffers.
There are several ways to instruct the compiler that pointers are not aliased:
-
Use a comprehensive compiler option, such as -fno-alias (Linux*) or /Oa (Windows*). These options instruct the compiler that no pointers in any module are aliased, placing the responsibility of program correctness directly with the developer.
-
Use a less comprehensive option, like -fno-fnalias (Linux) or /Ow (Windows). These options instruct the compiler that no pointers passed through function arguments are aliased.
Function arguments are a common example of potential aliasing that you can clarify for the compiler. You may know that the arguments passed to a function do not alias, but the compiler is forced to assume so. Using these options tells the compiler it is now safe to assume that these function arguments are not aliased. This option is still a somewhat bold statement to make, as it affects all functions in the module(s) compiled with the -fno-nalias (Linux) or /Ow (Windows) option.
-
Use the ivdep pragma. Alternatively, you might use a pragma that applies to a specified loop in a function. This is more precise than specifying an entire function. The pragma asserts that, for a given loop, there are no vector dependencies. Essentially, this is the same as saying that no pointers are aliasing in a given loop.
-
Use of keyword restrict. An even more precise method of disambiguating pointers is the restrict keyword. The restrict keyword is used to identify individual pointers as not being aliased. You would use the restrict keyword to tell the compiler that a given memory location is not written to by any other pointer.
The following example demonstrates using the restrict keyword to tell the compiler that the memory address pointed to by z is not written to by any other pointer. With this new information the compiler can then vectorize or software pipeline the loop as follows:
|
Example |
|---|
|
// One-dimension array. void restrict1(int *x, int *y, int * restrict z) { int A = 42; int i; double temp; for(i=0;i<100;i++) { z[i] = A * x[i] + y[i]; } } // Two-dimension array. void restrict2(int a[][100], int b[restrict][100]) { /* ... */ } |
 Caution
Caution
To use the restrict keyword as in the example above, you must also use the -restrict (Linux*) or /Qrestrict (Windows*) option on the compile line.
Non-Unit Stride Memory Access
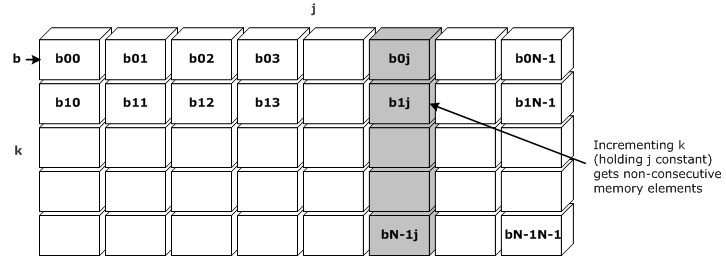
Another issue that can have considerable impact on performance is accessing memory in a non-Unit Stride fashion. This means that as your inner loop increments consecutively, you access memory from non adjacent locations. For example, consider the following matrix multiplication code:
|
Example |
|---|
|
// Non-Unit Stride access problem with b[k][j] void non_unit_stride(int **a, int **b, int **c) { int A = 42; for(int i=0; i<A; i++) for(int j=0; j<A; j++) for(int k=0; k<A; k++) c[i][j] = c[i][j] + a[i][k] * b[k][j]; } |
Notice that c[i][j], and a[i][k] both access consecutive memory locations when the inner-most loops associated with the array are incremented. The b array however, with its loops with indexes k and j, does not access Memory Unit Stride. When the loop reads b[k=0][j=0] and then the k loop increments by one to b[k=1][j=0].
Loop transformation (sometimes called loop interchange) helps to address this problem. While the compiler is capable of doing loop interchange automatically, it does not always recognize the opportunity.
The memory access pattern for the example code listed above is illustrated in the following figure:
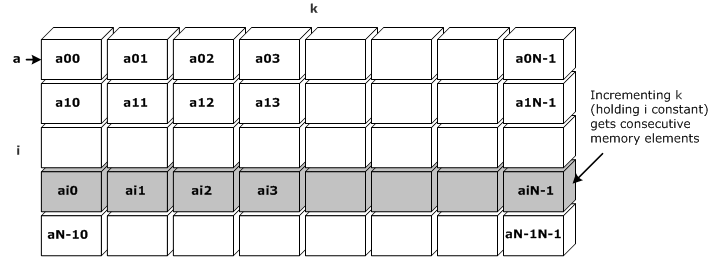
Assume you modify the example code listed above by making the following changes to introduce loop interchange:
|
Example |
|---|
|
// After loop interchange of k and j loops. void unit_stride(int **a, int **b, int **c) { int A = 42; for(int i=0; i<A; i++) for(int k=0; k<A; k++) for(int j=0; j<A; j++) c[i][j] = c[i][j] + a[i][k] * b[k][j]; } |
After the loop interchange the memory access pattern might look the following figure: